
Son numerosos los tutoriales en Internet que explican cómo montar un servidor Node-RED sobre GCP haciendo uso de clústers. Sin embargo cuesta encontrar (si es que los hay), tutoriales sobre como desplegar dicho servidor en una instancia, por lo que en este tutorial, nos centraremos en este caso. ¿Te suena a chino todo lo que hemos dicho? ¿Por qué montarlo sobre una instancia y no un clúster? Expliquemos brevemente los conceptos más raros de la frases anteriores para entendernos mejor.
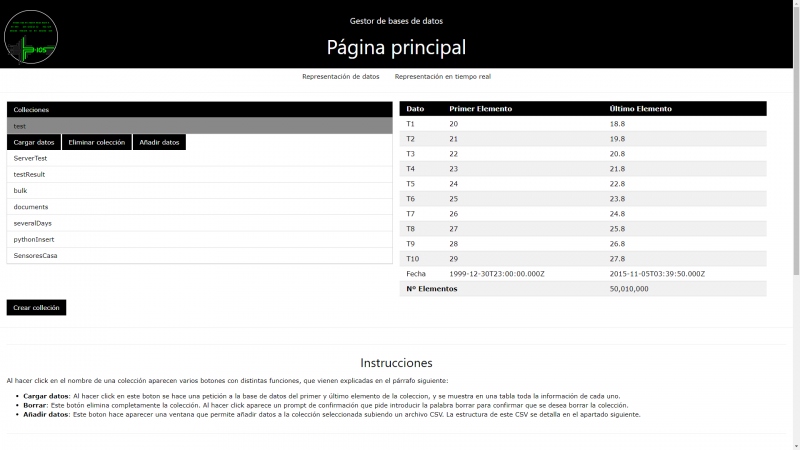
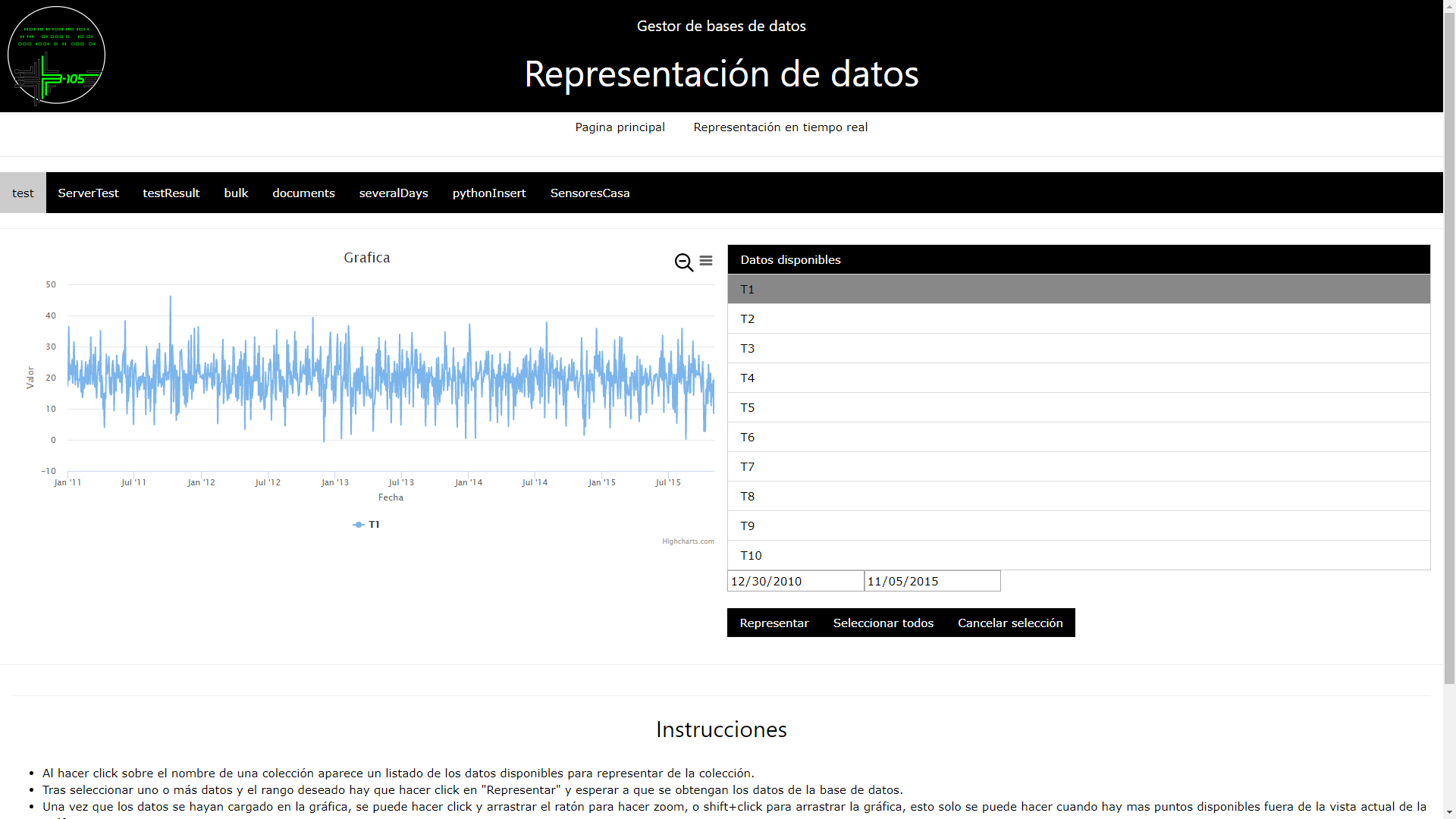
- Node-RED: es una herramienta de programación, de libre distribución, la cual nos permite de una forma rápida, y sobretodo muy intuitiva, desplegar una web con un estilo moderno y funcional. Node-RED hace uso de la programación “en cajas”, en la cual interconectamos distintos bloques ya pre hechos de las librerías disponibles. Node-RED usa Javascript y permite introducir bloques con nuestro propio código, pero para las tareas más sencillas no será siquiera necesario saber Javascript. Un ejemplo de un desarrollo simple en Node-RED sería el siguiente:
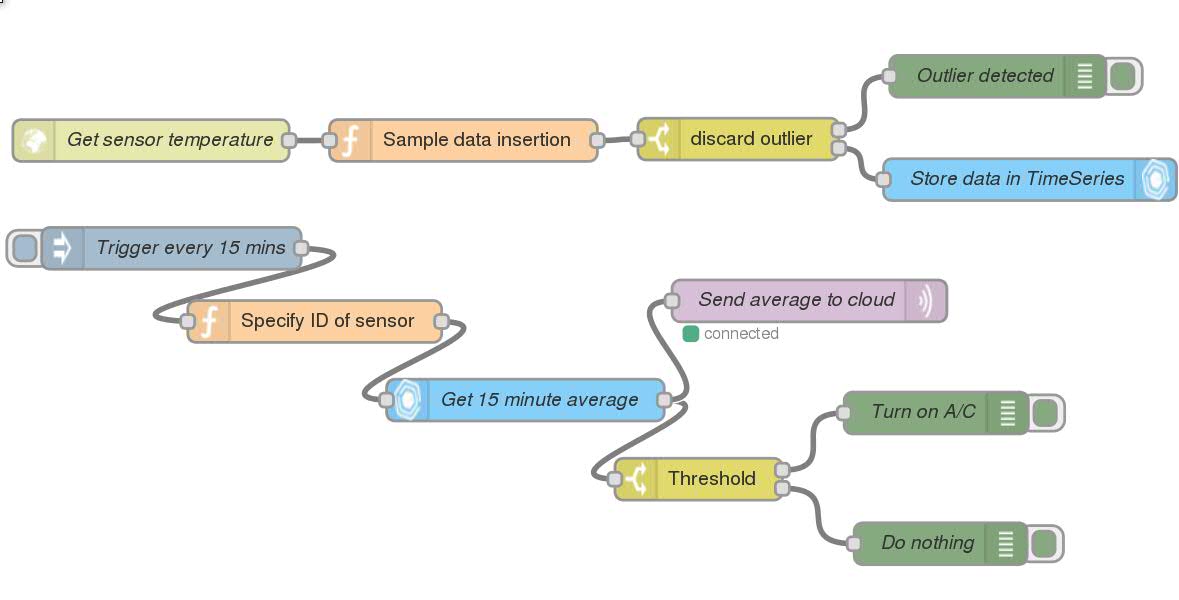
Node-RED permite además añadir librerías creadas por usuarios, siendo la librería “dashboard” una de las más populares, pues incorpora cajas con elementos visuales que permiten la interacción con el usuario así como la visualización de datos. Un ejemplo de ello:
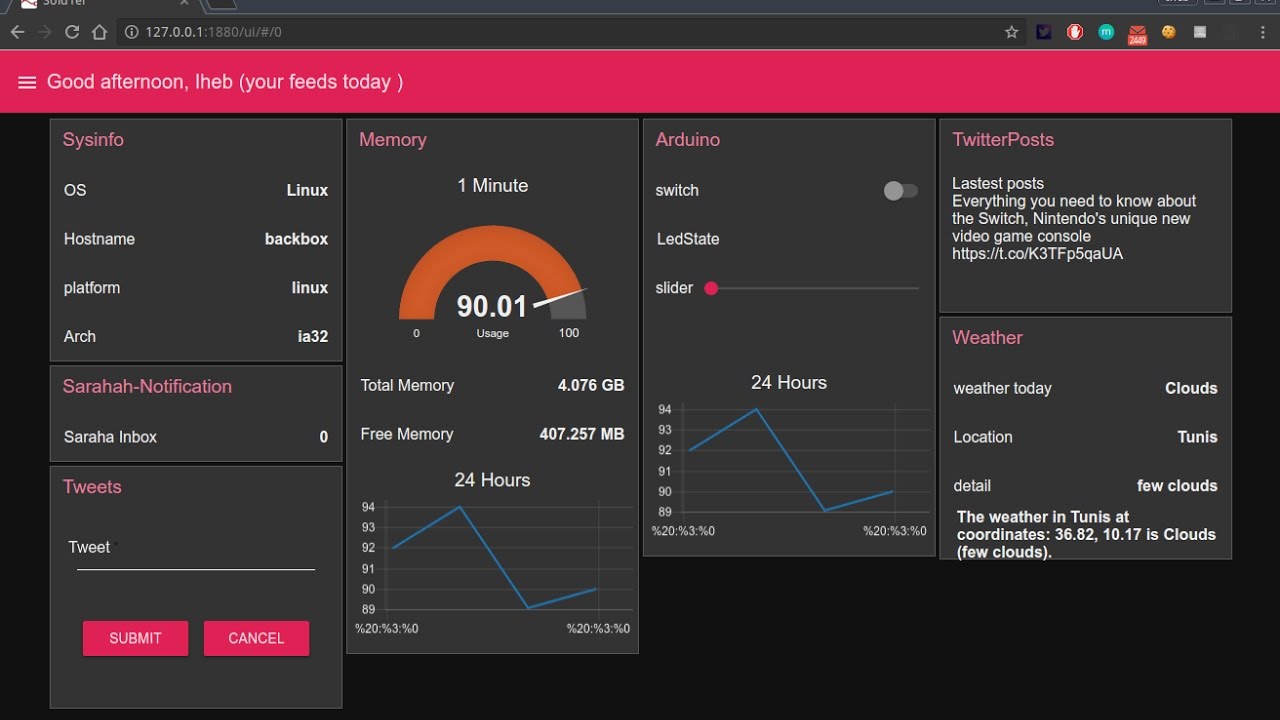
¿Fácil, verdad? Quien diría viendo esa web que se ha hecho sin necesidad de saber ningún lenguaje, solo juntando las cajas correctas. Existen otras opciones, como thingsboard.io, pero para gustos los colores, además de no ser la mayoría gratuitas (o tener planes gratuitos muy limitados). Nosotros preferimos Node-RED porque integra soporte para comunicaciones por UDP, TCP y el reciente MQTT, lo que permite comunicaciones con cualquier tipo de dispositivo, especialmente con dispositivos IoT. Además, la comunidad de desarrolladores es enorme y podemos encontrar muchos ejemplos ya hechos para su libre distribución, siendo estos ejemplos a veces, justo lo que buscamos.
Tenemos muchas formas de ejecutar Node-RED, en nuestro PC (esto es corriendo en un servidor local), en páginas que ponen a nuestra disposición servidores ya montados y listos para empezar a trabajar (FRED) o en servidores virtuales privados (VPS) de los cuales hay cientos de ofertas en Internet (aunque destacan por su catálogo y precios Microsoft Azure, Amazon Web Services [AWS] y Google Cloud Platform [GCP]). Las ventajas de ejecutar nuestro entorno en un VPS frente a nuestro ordenador o un entorno ya hecho (y cerrado) son inmensas: disponibilidad total, herramientas de protección, escalabilidad, no compromiso de nuestros datos privados, gestión de recursos… y esas son solo alguna de ellas.
- Google Cloud Platform: es uno de los tantos servicios de gestión de VPS que hay hoy en día. Si bien es cierto que uno de los que más fuerza tiene es AWS, Google ofrece algo que no ofrece el resto: un servidor gratuito al año con 24/7 en ejecución. Vale que es un servidor muy modestito (10 GB de almacenamiento; 0.6 GB de RAM y un único procesador), pero es gratis y para diseños simples puede ser más que suficiente. Es por esto que nos centraremos en este gestor VPS en este tutorial.
- Instancia vs. cluster: Google denomina a cada uno de los VPS que creamos instancia. Un grupo de instancias trabajando de forma conjunta, compartiendo recursos y distribuyéndose el tráfico de red entre ellas forma un clúster. Claro, a priori parece que el clúster es mejor (y lo es), pero no es gratis. La instancia, sin embargo, sí. Siempre y cuando esa instancia sea de las más simples de Google, como ya hemos comentado antes.
Ahora que ya hemos explicado todo un poco, relee si quieres el primer párrafo del post. Ahora ya parece obvio por qué queremos desplegar Node-RED (y no otro) sobre una instancia (y no un clúster), porque…

Empecemos…
Lo primero, lógicamente, es tener una cuenta de Google activa. Nos dirigiremos a la consola de Google Cloud y activaremos nuestra cuenta, registrándonos en la versión de prueba gratuita. Solo por registrarnos Google nos regala 300 $ en servicios GCP. Para nuestros propósitos no nos harán falta, pero nos vendrán genial si queremos cacharrear con todas las opciones que GCP ofrece. Completaremos todos nuestros datos (incluida la tarjeta de crédito, pero no pasa nada: Google nos avisará previamente en caso de que hiciéramos algo que incurriera en un desembolso). Tras registrarnos se nos creará nuestro primer proyecto (que podremos renombrar si queremos pinchando en configuración de proyecto).
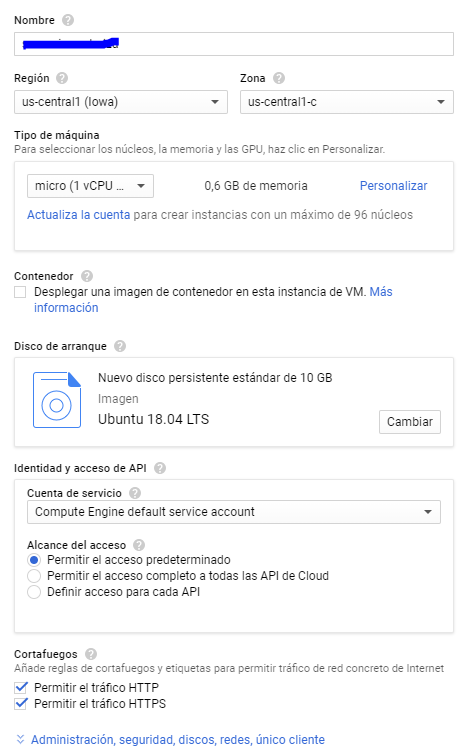
En el buscador escribimos Compute Engine y en la nueva ventana, una vez cargue, creamos una nueva instancia, con la configuración que vemos en la siguiente imagen:
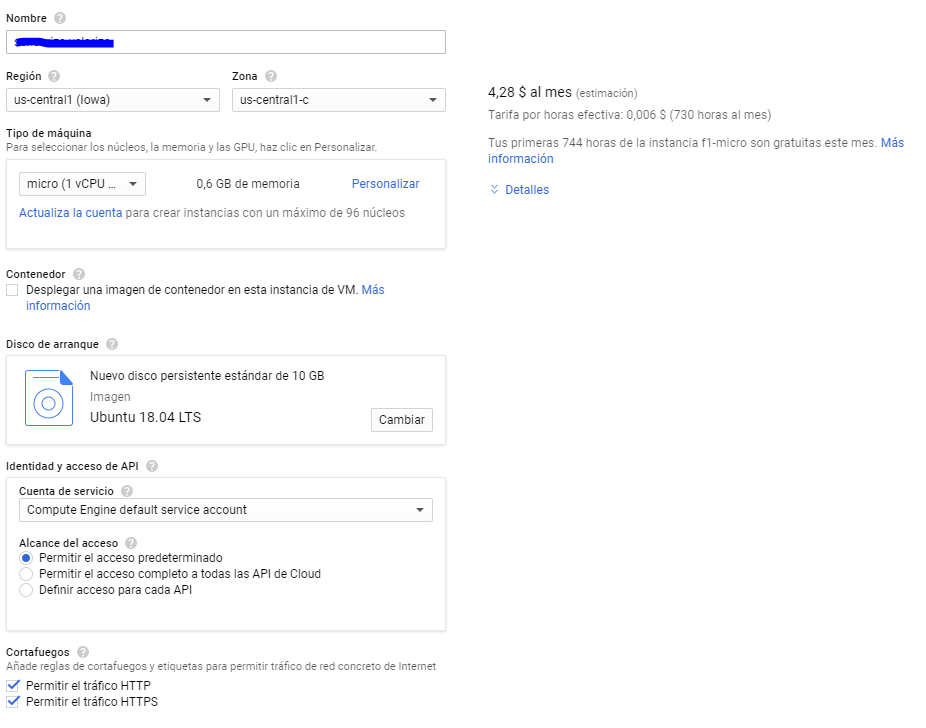
La zona da igual siempre que sea en América (salvo Virginia del Norte). América es la única región con VPS gratuitas. El tipo de máquina ha de ser micro y permitir el tráfico HTTP y HTTPS. Nosotros hemos elegido Ubuntu por familiaridad con los comandos, pero cualquier otra distribución de las gratuitas que ofrece Google es válida. Notad que para saber que estáis siguiendo los pasos correctos, debe apareceros el texto de la derecha donde os informa de que la máquina seleccionada es gratuita. Pulsamos en crear y esperamos.
Una vez creada, hay diferentes cosas que sería interesante hacer antes de empezar a cacharrear (asignarnos una IP estática y abrir algunos puertos).
-Asignando IP estática podremos entrar en nuestro servidor sin necesidad de consultar qué IP nos ha concedido Google esta vez: siempre será la misma. Para ello escribimos Red de VPC en el buscador y entraremos en la sección del menú lateral izquierdo “Direcciones IP externas”. Seleccionaremos nuestra instancia y cambiaremos su tipo a estática. Le ponemos un nombre identificativo a esta IP y aceptamos.
-Abriendo puertos (bien sea TCP o UDP) permitiremos un acceso remoto a nuestro servidor. Hay que notar que esto es un arma de doble filo, pues si bien no podemos hacer mucho sin tener acceso a nuestro servidor remoto también es una puerta abierta a hackers, por lo que recomendamos abrir solamente los puertos que vayamos a necesitar. En nuestro caso será obligatorio abrir el puerto TCP 1880, pues será el que usará Node-RED tanto para la interfaz de diseño (donde colocaremos las cajitas) como para la interfaz web (donde nos mostrará el resultado de colocar y conexionar esas cajitas). Para ellos tecleamos en el buscador “Reglas de cortafuegos” y elegimos la opción que lleve también escrito Red de VPC.
Creamos una regla nueva: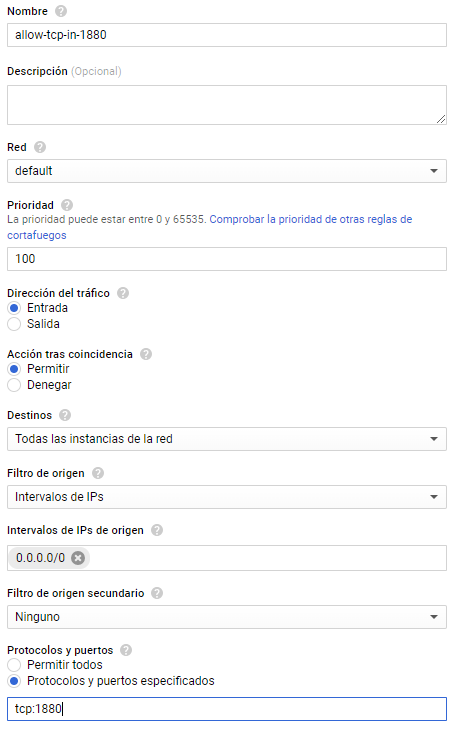
El nombre es opcional, todo lo demás, recomiendo dejarlo a esos valores. Cuando cojáis más soltura con GCP os recomiendo etiquetar vuestras distintas instancias para poder elegir destinos de reglas del cortafuegos y así que cada máquina tenga abiertos los puertos que necesita. Por ahora, y como solo tenemos una máquina creada, no pasa nada por aplicar en el campo destinos “todas las instancias de la red”. Guardamos y ya estaremos listos para empezar la instalación de Node-RED sobre nuestro VPS.
Volvemos a la vista de Compute Engine, donde estará nuestra instancia. En el campo “Conectar” pulsamos sobre SSH. Se nos abrirá una ventana nueva y cuando cargue ya estaremos dentro de nuestro VPS.
Para poder empezar a trabajar, tecleamos los siguientes comandos:
|
1 2 3 4 5 |
sudo apt-get install build-essential curl -sL https://deb.nodesource.com/setup_8.x | sudo -E bash - sudo apt-get install -y nodejs |
Nótese que entre los comandos, se instalará nodejs. En nuestro caso hemos instalado la versión 8.x por ser la recomendada en el momento de realizar este tutorial, pero se aconseja mirar en la página de nodejs cual es la última versión recomendada. Escribimos ahora el comando que instalará Node-RED en nuestro VPS.
|
1 |
sudo npm install -g --unsafe-perm node-red |
Es también interesante instalar algunas herramientas de node-red que nos harán más fácil la gestión de nuestro servidor, por lo que teclearemos:
|
1 |
sudo npm install -g node-red-admin |
Después de esto ya podemos probar que Node-RED está correctamente instalado. Para ellos tecleamos:
|
1 |
node-red |
Lo que debería arrojar en el terminal una salida que acaba con:
|
1 2 3 |
18 Jul 18:23:53 - [info] Server now running at http://127.0.0.1:1880/ 18 Jul 18:23:53 - [info] Starting flows 18 Jul 18:23:53 - [info] Started flows |
Esto es indicativo de que todo está correcto. ¡Probémoslo! Escribamos en nuestra barra del navegador la IP estática concedida por Google (sin http ni https delante seguida del puerto de acceso a Node-RED, separado por dos puntos “:”), algo así como 123.123.123.123:1880. Deberíamos ver esto:
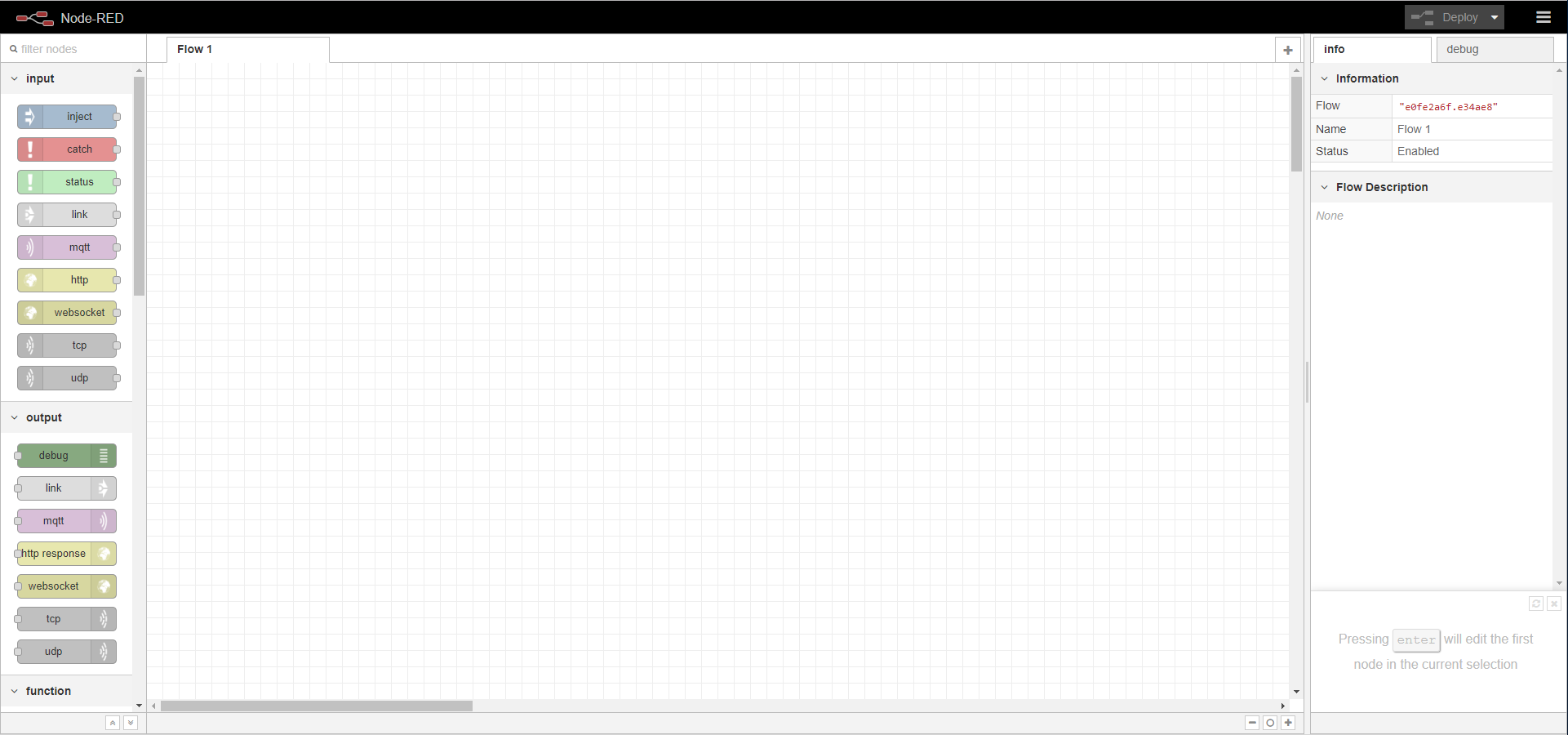
¡Todo funciona! Sin embargo esto presenta un enorme, enorme inconveniente: cualquiera que sepa nuestra IP puede acceder a nuestro servidor Node-RED y borrarnos todo el trabajo o inyectar código malicioso. Por ello, el siguiente paso, de vital importancia, es proteger nuestro servidor. Volviendo a la terminal abierta por SSH, pulsamos ctrl+C para parar la ejecución de Node-RED y escribiremos:
|
1 |
node-red-admin hash-pw |
Lo que nos preguntará por la contraseña con la que deseamos proteger el servidor. Tras escribirla y pulsar intro, nos devolverá una secuencia hash con nuestra contraseña encriptada, que deberemos copiar, pues usaremos ahora. Escribiremos sobre el archivo de configuración de Node-RED. En el terminal tecleamos:
|
1 |
sudo nano ~/.node-red/settings.js |
y dentro de este archivo buscaremos el siguiente texto:
adminAuth: {
type: “credentials”,
users: [{
username: “USUARIO“,
password: “HASH_GENERADO“,
permissions: “*”
}]
},
// To password protect the node-defined HTTP endpoints (httpNodeRoot), or
// the static content (httpStatic), the following properties can be used.
// The pass field is a bcrypt hash of the password.
// See http://nodered.org/docs/security.html#generating-the-password-hash
httpNodeAuth: {user:”USUARIO“,pass:”HASH_GENERADO“},
httpStaticAuth: {user:”USUARIO“,pass:”HASH_GENERADO“},
En usuario escribiremos el usuario que queramos, y en los campos password y pass, el hash generado anteriormente. La primera parte protegerá la parte de gestión (donde colocamos las cajitas), la segunda, la parte de visualización (la web que crean las cajitas). Es importante descomentar las lineas necesarias (esto es, eliminar los caracteres “//” con los que empiezan algunas lineas), para que el resultado quede tal y como hemos puesto arriba. Guardamos con CTRL+O y salimos con CTRL+X.
Por último, será interesante que nuestro servidor cargue automáticamente Node-RED cuando se reinicie, lo que hará más tolerante a fallos nuestra implementación. Para ello, escribimos:
|
1 |
whoami |
Que nos indicará nuestro nombre de usuario. A continuación:
|
1 |
sudo nano /etc/systemd/system/node-red.service |
donde copiaremos el siguiente texto:
[Unit]
Description=Node-RED
After=syslog.target network.target
[Service]
ExecStart=/usr/bin/node-red
Restart=on-failure
KillSignal=SIGINT
# log output to syslog as ‘node-red’
SyslogIdentifier=node-red
StandardOutput=syslog
# non-root user to run as
WorkingDirectory=/home/TUUSUARIO/
User=TUUSUARIO
Group=TUUSUARIO
[Install]
WantedBy=multi-user.target
Hay que modificar solo los campos en rojo. Nuevamente, guardamos con CTRL+O y salimos con CTRL+X. Activamos el servicio creado escribiendo:
|
1 |
sudo systemctl enable node-red |
Comprobaremos que todo se haya hecho correctamente. Para ello primero es necesario reiniciar, por lo que escribimos:
|
1 |
sudo reboot |
Y tras esperar unos dos minutos, cargamos de nuevo la página con la IP del servidor en nuestro navegador. Ahora, al cargar node-RED debería pedirnos login, tanto a la parte de gestión como a la de visualización.
¡Eso es todo por nuestra parte! Ahora, a jugar.










{kind=link}